Local LLMs are fast enough for real coding work now. You can easily fit very capable model to a machine with 32GB of RAM. On Apple Silicon with the right engine, you get 100+ tokens per second from a model like Qwen3.5 32B that can write, refactor, and debug production code. It offers reliable tool calling within any coding agent with only 3B active parameters. Check out what the CTO at HuggingFace has to say about it (post on LinkedIn):
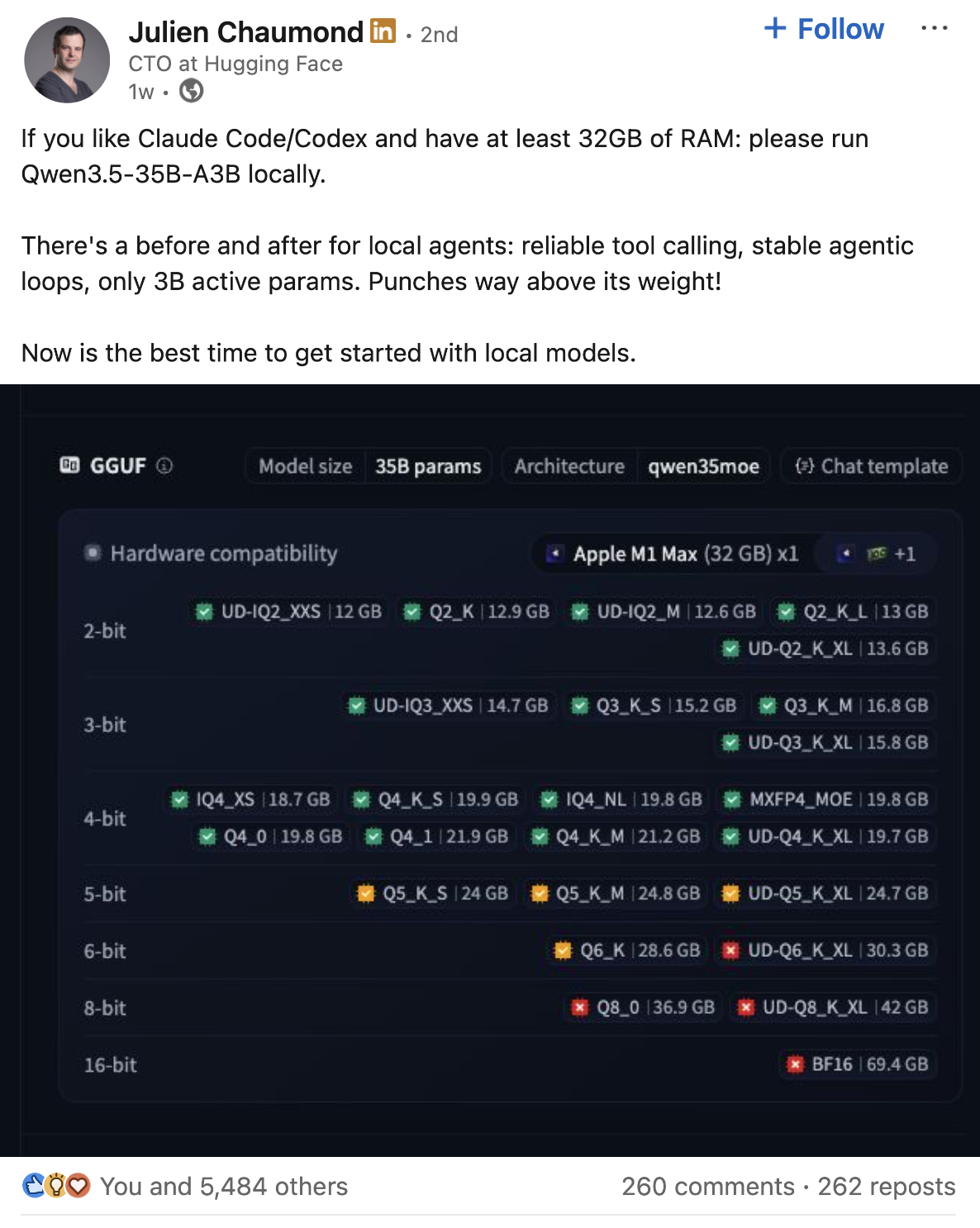
In this blog, we benchmark three inference engines to see which one is the best (read: fastest) for daily agentic coding work. My hardware for the tests: M4 Max with 128GB unified memory, but keep in mind that 128GB is overkill for this model. At 4-bit quantization, which is near-lossless for this MoE architecture1, it uses around 20GB of RAM. So something like ~$1400.00 MacBook Air with 24GB of RAM will do the trick. Yes, you can get more powerful hardware for the money. But the fastest engine in this benchmark only runs on macOS.
Why Qwen3.5?
Qwen3.5 uses a Mixture-of-Experts (MoE) architecture. Its flagship version has 397B parametrs, but only around 17B active per token. With this architecture, it ranks among the top open-weight models on Artificial Analysis, competing with Kimi K2.52 on coding and agentic tasks and scoring highest on their Coding Index3:
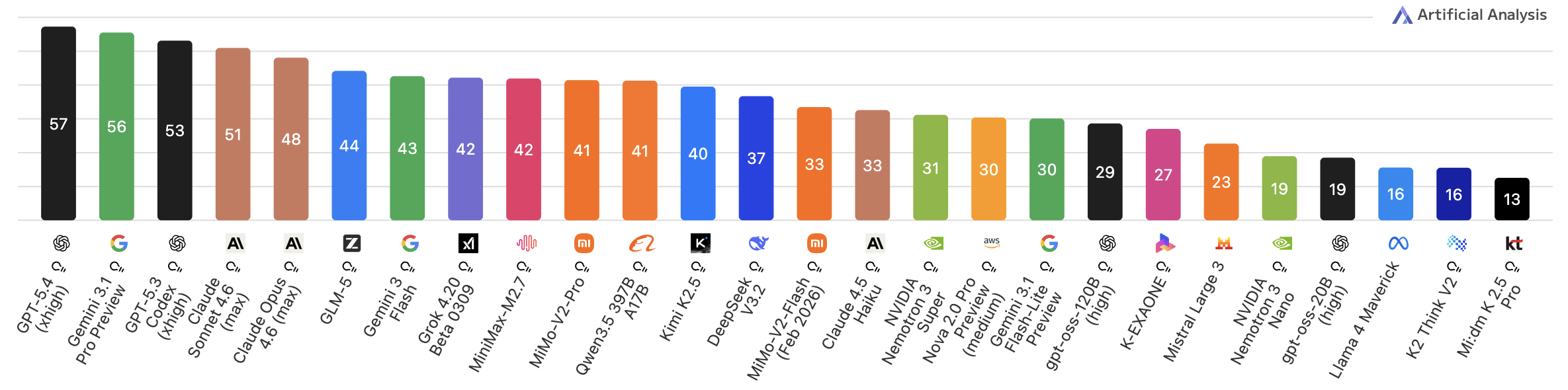
When it comes to proprietary models, it ranks on par with models such as Gemini 3 Flash and is order of magnitude above Claude 4.5 Haiku on Inteligence Index4:
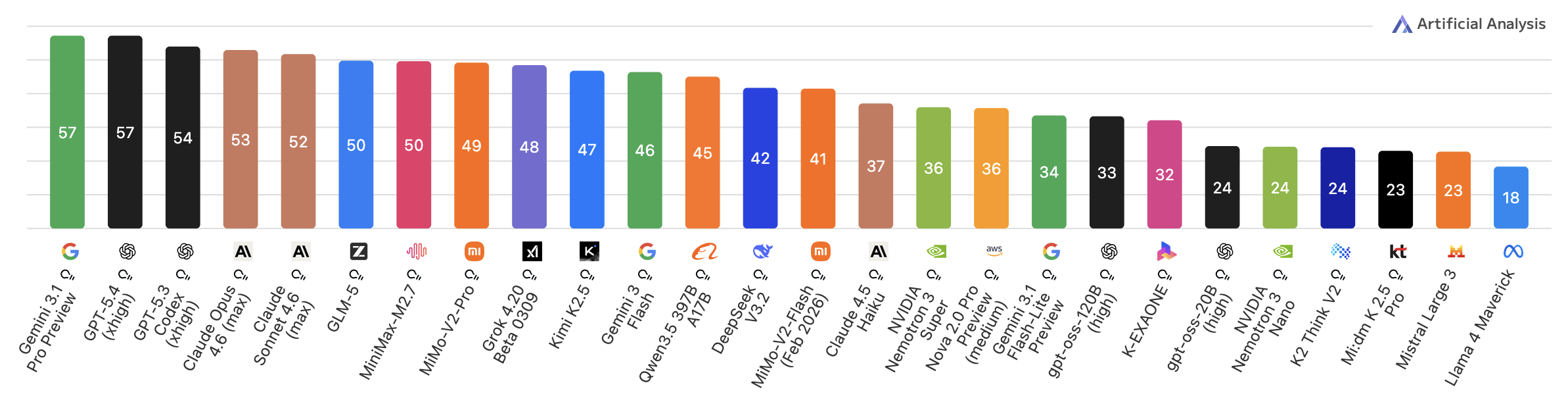
However on Agentic Index5, it ouperforms following models: Grok 4.20, Gemini 3 Flash, and even Claude 4.5 Haiku. It is on par with Gemini 3.1 Pro Preview and only slightly below GPT-5.3 Codex (yes, $1.75 per 1M input tokens and $14.00 per 1M output tokens GPT-5.3 Codex xhigh):
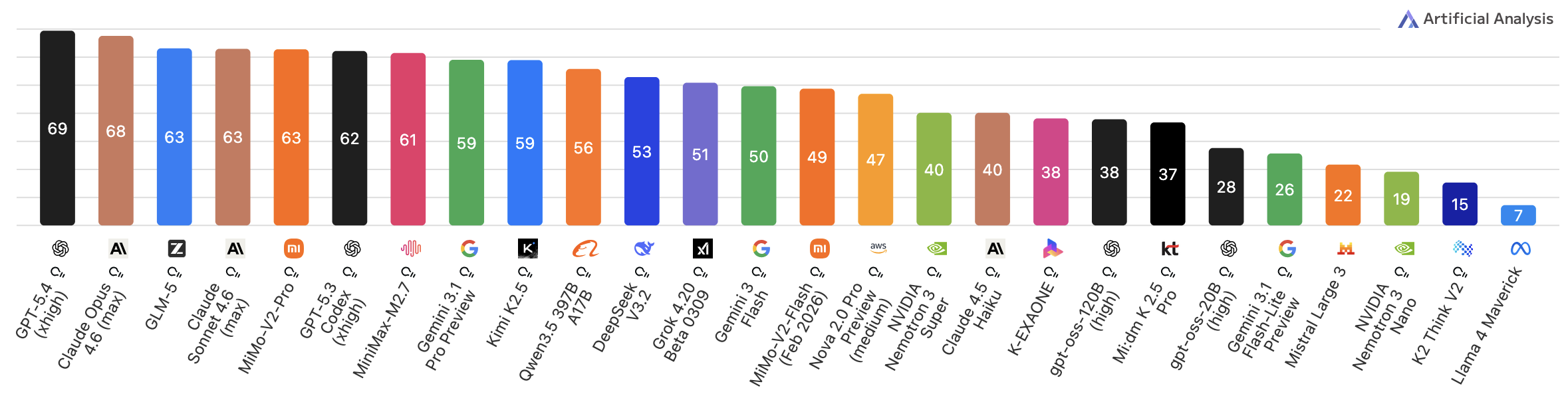
The 35B-A3B is the local-friendly model in that same family. Even though it at about 75% of capabilites compared to the flagship6, it’s fairly good performer across general intelligence, coding, and agentic tasks.
The Engines
Ollama is the easiest way to get started. Simply run ollama pull qwen3.5:35b and you’re ready. It wraps GGUF models behind a simple API and handles model management natively. However, the tradeoff is performance as we’ll see below.
llama.cpp gives you full control. You pick the quantization, set context size, enable flash attention, etc. It’s more setup, but you’re running the ggml runtime directly without a wrapper layer.
MLX is Apple’s ML framework built specifically for Apple Silicon. It leverages unified memory directly, and it’s macOS only. We’ll see results in two seperate modes: HTTP server (usually what harnesses use to access the model) and direct Python API (the theoretical ceiling without network overhead).
Quantization
Each engine runs a slightly different quantization, and that’s intentional.
Ollama uses Q4_K_M, which averages around 4.5 bits per weight. This is the standard GGUF quantization you get with ollama pull out of the box.
llama.cpp uses Unsloth Dynamic Q4_K_XL. Important layers like attention and MoE routing get upcast to 8 or 16-bit precision while the rest stays at 4-bit. Slightly larger, slightly more accurate. And ironically, slightly faster. Read on…
MLX uses 4-bit group quantization in its native format, optimized for Apple GPU execution.
This means we’re not comparing quants against each other. Each engine runs its recommended default. The benchmark measures what you’d actually run in practice. This is a known limitation, so keep it in mind when comparing numbers across engines.
Sampling Parameters
We test two parameter sets per engine.
Deterministic uses temperature 0 and max tokens of 2048. Fully reproducible greedy decoding. A stable baseline for comparing engines.
Coding mode uses temperature 0.6 and top_p 0.95 with the same 2048 max tokens. These come from Unsloth’s recommendation for “precise coding tasks” in thinking mode. This is what I use in opencode for my actual work.
Both parameter sets are tested with thinking mode on and off, giving four configurations per engine.
Benchmark Methodology
Hardware. Apple M4 Max, 128GB unified memory, macOS 26.3.
Prompt. “Write a Python function that prints FizzBuzz for numbers 1 to 100.” Simple and short. This keeps prompt processing out of the way and focuses on generation speed.
Protocol. A single warmup run (discarded) followed by 10 measured runs per configuration. All apps closed, power plugged in.
Metrics. Two measurements per run: native generation tok/s (reported by the engine itself, usually as eval_rate) and client-side generation tok/s (wall-clock timing). Capturing both isolates the HTTP overhead.
Matrix. 4 engines x 2 thinking modes x 2 parameter sets x 10 runs = 160 total measured runs.
Known limitations. Different quantizations per engine (see above). Context size is set to 65536 for Ollama and llama.cpp, dynamic for MLX. With a short prompt, context size does not affect generation speed.
The full benchmark script is on GitHub.
Results
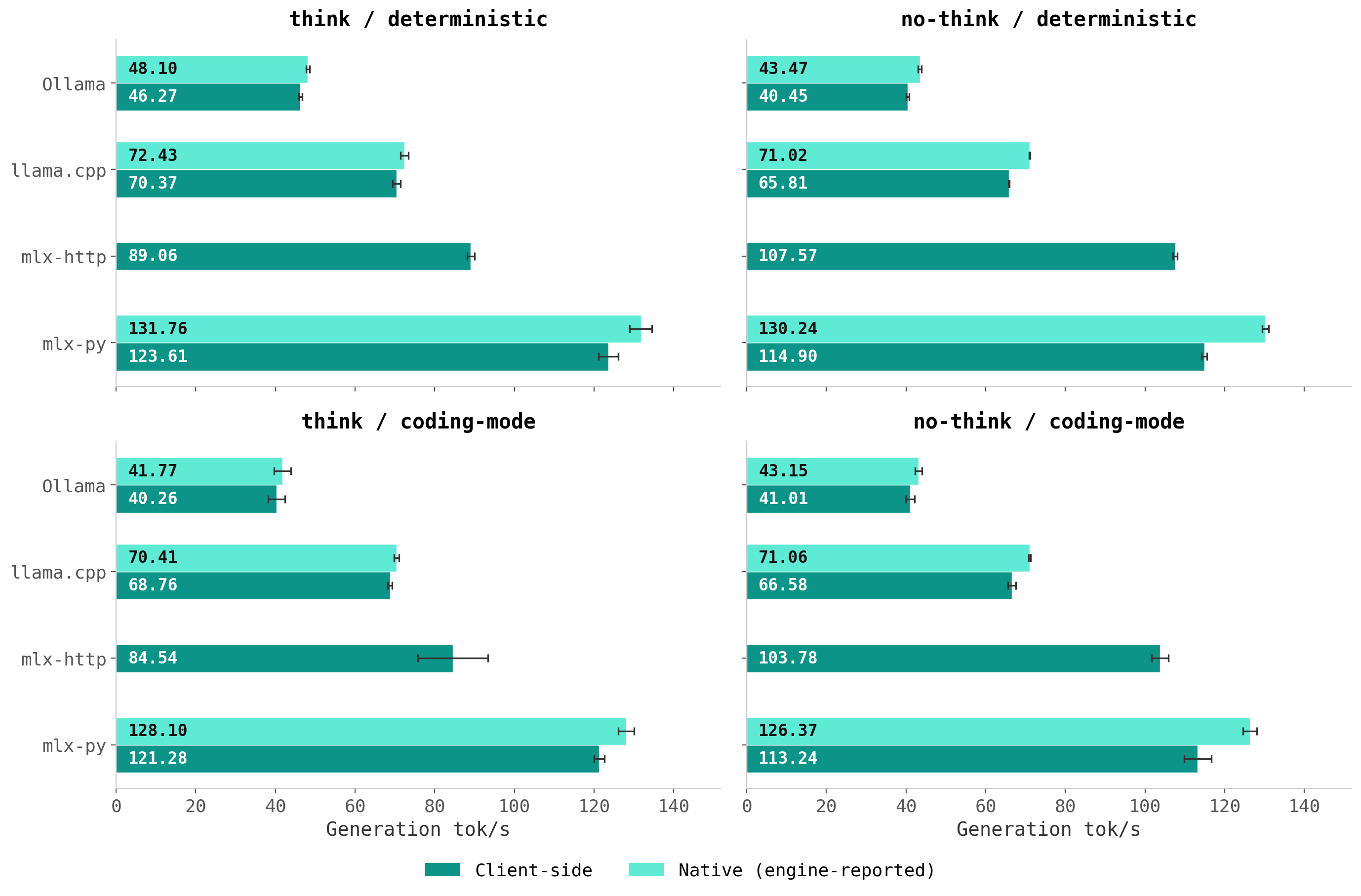
The full numbers with standard deviations are available on GitHub and listed in the appendix.
MLX is the fastest. Around 130 tok/s native via the Python API, 90-108 tok/s via the HTTP server. Even the HTTP path is more than 2x faster than Ollama.
llama.cpp is a solid middle ground. Roughly 71 tok/s, consistent across all configurations.
Ollama is by far the slowest. Around 43 tok/s. Convenience comes at a cost.
HTTP overhead is real. MLX Python vs. MLX HTTP shows a roughly 20% gap. That’s probably TCP, SSE, and JSON parsing overhead. Tools like opencode go through HTTP, so in practice you get the HTTP numbers.
Thinking mode doesn’t affect speed. The decode loop is the same regardless. Thinking mode just produces more tokens, but the per-token rate stays consistent.
Deterministic vs coding params. Negligible difference on throughput.
What these numbers feel like. Around 40 tok/s is readable but feels sluggish during coding. 70 tok/s is comfortable. 100+ tok/s feels instant, with text appearing faster than you can read it.
Day-to-Day with opencode
opencode is an open-source terminal coding agent. Based on the results above, MLX HTTP is the practical winner for Apple Silicon. Fast enough at 90-108 tok/s, simple to run, and compatible with any OpenAI-compatible client.
I use two shell aliases to manage the server:
alias mlx-start='if ! lsof -i :8082 &>/dev/null; then
mlx_lm.server \
--model ~/.local/share/mlx-models/Qwen3.5-35B-A3B-4bit \
--port 8082 \
> /tmp/mlx-server.log 2>&1 &
disown;
echo "mlx-server started (pid $!)";
else echo "mlx-server already running on :8082"; fi'
alias mlx-stop='kill $(lsof -ti :8082) 2>/dev/null && echo "mlx-server stopped" || echo "mlx-server not running"'
Then the opencode config at ~/.config/opencode/opencode.json:
{
"agent": {
"coder": {
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"min_p": 0.0
}
},
"provider": {
"mlx": {
"models": {
"default_model": {
"name": "Qwen3.5-35B-A3B"
}
},
"name": "MLX",
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://127.0.0.1:8082/v1"
}
}
}
}
The temperature and top_p values come from Unsloth’s recommendation for precise coding in thinking mode. The workflow is simple: mlx-start, open opencode, ?, profit.
That’s It
Local inference on Apple Silicon is practical for real coding work today. MLX gets you 100+ tok/s through an HTTP server, which is fast enough that the model is never the bottleneck.
Why Apple Silicon specifically? Well, the results tell pretty much the whole story. MLX is 2-3x faster than ollama and roughly 1.5x faster than llama.cpp. It’s the clear winner, and it only runs on macOS. Ollama and llama.cpp work on any platform, but they top out at 48 and 72 tok/s respectively on this specific hardware. You might have a Lenovo with better raw specs on paper, but without MLX, you’re leaving the fastest engine on the table. The combination of unified memory and Apple’s native ML framework is what makes the difference. For local LLM inference today, that’s the argument for Mac. That is unless of course you have your own private GB300 DGX Station like some of us do.
The benchmark script is on GitHub. Run it on your own hardware and see how your setup compares.
Appendix: Full Results Table
| Engine | Thinking | Params | Gen tok/s (native) | Gen tok/s (client) |
|---|---|---|---|---|
| mlx-py | no | deterministic | 130.2 +/- 0.8 | 114.9 +/- 0.7 |
| mlx-py | no | coding | 126.4 +/- 1.7 | 113.2 +/- 3.4 |
| mlx-py | yes | deterministic | 131.8 +/- 2.8 | 123.6 +/- 2.5 |
| mlx-py | yes | coding | 128.1 +/- 2.0 | 121.3 +/- 1.3 |
| mlx-http | no | deterministic | N/A | 107.6 +/- 0.6 |
| mlx-http | no | coding | N/A | 103.8 +/- 2.2 |
| mlx-http | yes | deterministic | N/A | 89.1 +/- 1.0 |
| mlx-http | yes | coding | N/A | 84.5 +/- 8.8 |
| llamacpp | yes | deterministic | 72.4 +/- 1.0 | 70.4 +/- 1.0 |
| llamacpp | no | coding | 71.1 +/- 0.3 | 66.6 +/- 1.0 |
| llamacpp | no | deterministic | 71.0 +/- 0.1 | 65.8 +/- 0.1 |
| llamacpp | yes | coding | 70.4 +/- 0.6 | 68.8 +/- 0.6 |
| ollama | yes | deterministic | 48.1 +/- 0.4 | 46.3 +/- 0.4 |
| ollama | no | deterministic | 43.5 +/- 0.4 | 40.5 +/- 0.4 |
| ollama | no | coding | 43.1 +/- 0.8 | 41.0 +/- 1.1 |
| ollama | yes | coding | 41.8 +/- 2.1 | 40.3 +/- 2.1 |
Footnotes
Unsloth benchmarked 150+ quantization configs for Qwen3.5-35B using KL Divergence, showing that Dynamic 4-bit quantizations (Q4_K_XL, Q4_K_M) retain near-original accuracy. Key quality-sensitive layers (attention, SSM) stay at higher precision while MoE feed-forward layers tolerate aggressive quantization well. See Unsloth GGUF Benchmarks. ↩︎
Note that Kimi is 3x the size with around 1T parameters in total! ↩︎
Coding Index is calculated as the average of coding evaluations in the Artificial Analysis Intelligence Index (see one footnote below for more details). It includes the following evaluations: Terminal-Bench Hard, and SciCode. ↩︎
Artificial Analysis Intelligence Index v4.0 incorporates the following evaluations: GDPval-AA, 𝜏²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity’s Last Exam, GPQA Diamond, and CritPt. For further details, check out Intelligence Index Methodology. ↩︎
Agentic Index represents the average of agentic capabilities benchmarks in the Artificial Analysis Intelligence Index (GDPval-AA, 𝜏²-Bench Telecom). ↩︎
On Artificial Analysis Intelligence Index, 32B-parameter MoE model scores 37 vs. 45 by flagship model. Similarly, on Coding and Agentic index, differences are: 30 vs. 41 and 44 vs 56, respectively. ↩︎